개인적으로 아래과 같은 강의를 들으면서 DBMS에 관련해서 공부 중인 내용을 정리하려고 쓰는 포스팅입니다. 강의도 듣고 책도 읽고 정리하고는 있어도 제가 모자라서 틀린 부분이 있을 수도 있습니다. 혹시라도 발견하시면 댓글로 알려주시면 감사하겠습니다.
https://15445.courses.cs.cmu.edu/fall2019/
Which Storage Type?
저장소를 분류하는 방법에는 다양한 기준이 있겠지만 휘발성을 기준으로 나눠보자. 여기서 휘발성이란 전원을 껐을 때 담겨있던 정보가 사라지는 것을 의미한다.
휘발성이 있는 저장소의 대표격은 역시 RAM이다. 보통 메모리라고 퉁쳐서 부르기도 합니다. 그리고 비휘발성의 저장소 중 제일 대표적인 것은 HDD일 것입니다. 일반적으로 데이터베이스를 사용하는 상황은 전원이 켜져있든 꺼져있든 저장된 정보는 유지되어야 합니다. 쇼핑몰의 고객정보가 서버가 꺼지는 순간 다 사라진다면 큰 일이 일어나겠죠.
따라서, 현재의 DBMS는 Disk-Oriented입니다. HDD나 SSD, 혹은 네트워크 저장소가 disk를 말합니다.
1. Random Access VS Sequential Access
Random access란 원하는 주소에 바로 접근하는 것을 말합니다. 우리가 주소 10에 위치한 20바이트의 정보를 사용하고 싶다면 random access는 바로 주소 10에 접근해서 20바이트를 가지고 오는 것을 말합니다. 메모리에선 어떤 주소든 같은 속도로 Random Access를 지원합니다.
그럼 Sequential Access는 뭘 말하는걸까요? 저장소에서 어떤 주소를 접근하는 데에 있어서 어떠한 순서가 존재해서 해당 순서로만 접근하는 것을 말합니다. 디스크에는 이러한 sequential access만을 지원합니다.
따라서, random access를 하려고 하면 현재 상황에 따라서 그리고 어느 주소에 접근하려냐에 따라서 접근 속도가 크게 달라지게 됩니다. 그리고 이는 시간에 있어서 큰 차이를 가져옵니다. 그래서 데이터베이스가 디스크에 파일을 저장할 때는 주소 상에서 연속적으로 저장하는 것이 중요해집니다.
예시를 들자면 크기가 1000인 파일이 크기 50씩 20군데로 나뉘어 저장된 것은 random access가 20번 발생할 것이고 1000이 연속적으로 한 군데에 저장되었다면 random access가 한 번 발생한다고 생각하면 됩니다.
2. Byte-Addressable vs Block/Page-Addressable
메모리에 접근할 때는 어떤 주소에 있는 10바이트를 가져와라고 명령하면 정확히 그 주소에 가는 것이 가능합니다. 이런 식으로 바이트 단위로 주소 지정이 가능한 것을 Byte Addressable이라고 합니다.
반면에 디스크는 어떤 주소로 가라고 했을 때 그 주소가 있는 블록 혹은 페이지로 가서 해당 주소가 위치한 블록에 접근합니다. 이런 것을 Block/Page Addressable이라고 합니다.
위 두 특성때문에 데이터베이스 파일을 저장하거나 접근할 때, 가능한 연속적으로 또 가능한 한 블럭 안에 들어오도록 저장하는 방법을 신경쓸 필요가 있습니다.
그리고 디스크 접근은 굉장히 비쌉니다. 메모리에 접근하는 시간을 100초라고 가정했을 때 HDD에 접근하는 것은 16.5주에 해당하는 시간입니다.
DISK-ORIENTED DBMS Overview
데이터베이스 파일이 디스크에 존재한다고는 해도 쿼리를 처리하려면 결국 메모리 안으로 들고와야 합니다.
데이터베이스 파일은 머신이 가지고 있는 물리적 메모리보다 클 수도 있습니다. 그래서 DBMS는 디스크와 메모리 사이에서 파일을 어떻게 이동하고 저장할지를 관리합니다. DBMS가 메모리 상에서 buffer pool이라는 것을 만들고 처리가 필요한 파일 부분을 디스크에서 가지고와서 메모리에 올리고 또 필요 없어진 부분은 디스크로 보내며 메모리를 관리합니다.
파일을 전부 메모리에 올리진 못하기 때문에 DBMS는 파일을 구성할 때 애초에 여러 조각으로 나누어서 저장을 하는데 그 단위를 보통 page라고 부릅니다. 데이터베이스의 특정 영역에 접근하고 싶다고 buffer pool manager에게 명령이 들어오면 buffer pool manager는 해당 페이지가 현재 자신이 관리 중인 메모리 상에 존재하는지 체크합니다.
만약에 있다면 해당 내용을 반환하고 없다면 페이지 디렉토리라고 페이지를 관리하는 자료구조에 접근해서 해당 페이지의 위치를 찾습니다. 이 때, 페이지 디렉토리 또한 디스크에 존재하므로 만약에 메모리 상에 존재하지 않는다면 이를 먼저 디스크에서 들고 옵니다. 그렇게 요구한 페이지를 찾은 뒤에 디스크에서 메모리 상에 올립니다.
위와 같이 파일을 페이지로 구성하고 페이지 단위로 메모리와 디스크 사이에서 파일을 왔다 갔다 하는 이유는 메모리가 데이터베이스 파일에 비해 매우 작기 때문입니다. 전체를 메모리에 담을 수가 없으니 작은 단위로 필요한 부분을 올려놓고 필요 없어지면 내려놓고 하는거지요.
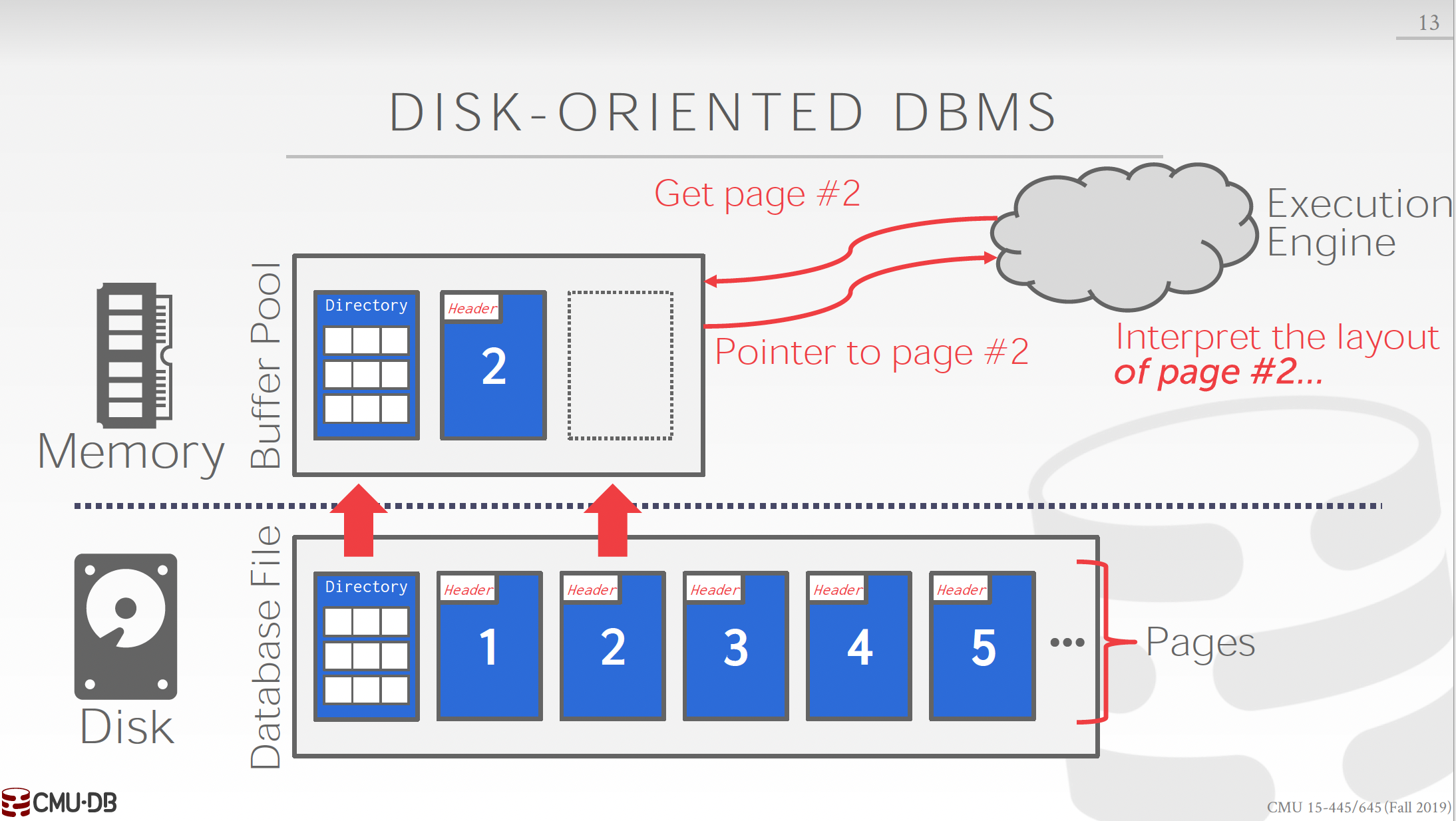
위 그림에서 Execution Engine이라는 DBMS의 일부가 Buffer Pool Manager에게 2번 페이지를 요구합니다. 이 때 페이지 디렉토리가 메모리 상에 없다면 이것부터 디스크에서 불러오고 그 뒤에 2번 페이지를 디렉토리에서 찾은 뒤에 들고 옵니다. 그 뒤에 메모리 상의 2번 페이지 주소를 execution engine에게 돌려줍니다.
위 일련의 과정과 매우 비슷한 일을 하는 프로그램이 하나 더 있습니다. 운영체제입니다. 운영체제는 실제 물리 메모리보다 더 큰 메모리를 프로세스에게 제공하기 위해서 프로세스 별로 Page Table을 관리하며 물리메모리와 가상메모리의 page를 맵핑해주는 역할을 합니다. 또한 물리 메모리가 부족해질 수도 있기 때문에 디스크에 스왑 공간을 따로 두어 buffer pool manager와 동일하게 디스크에 페이지를 내려놓기도 하고 끌어오기도 합니다.
심지어 운영체제에 파일과 메모리를 동기화시켜주는 시스템콜(mmap)도 존재하는데 왜 DBMS는 운영체제에게 이러한 메모리 관리를 맡기지 않고 직접 할까요?
DBMS VS OS
DBMS가 직접 디스크와 메모리 사이의 페이지 이동을 관리하려는 이유는 간단합니다. OS는 DBMS에서 요구하는 메모리 접근이 어떤 것인지 전혀 알지 못해서 성능을 크게 저하시키기 때문입니다.
DBMS의 입장에서는 현재 접근 중인 페이지들이 어떻게 쓰일 것인지도 알고 언제 쓸모가 없어질지도 다 아는 상태입니다. 그러나 OS는 모르죠. 그저 프로세스 하나가 read/write를 엄청 많이 할 뿐이에요. DBMS라는 프로그램은 태생적으로 디스크 I/O가 많기 때문에 이를 관리하는 것이 매우 큰 이슈입니다. 그런데 내가 뭘 하는지도 모르는 OS에게 그걸 전부 맡겨버릴 순 없죠. 실제 주요 DBMS들, Oracle, Sqlite, SQLServer, Postgresql, 여럿은 직접 page 관리를 한다.
How DBMS store database files?
데이터베이스 파일은 일단 페이지들로 나눠져서 구성된다고 했습니다. 그렇게 저장된다고 생각해도 되겠죠. 그런데 페이지들로 쪼갰다고 해도 그것을 어떤 형태로 관리하고 어떤 형태로 저장할지를 정해야 저장소를 관리해주는 프로그램(Storage Manager)도 파일들을 읽고 내보내고 할 수 있겠죠.
Storage Manager는 디스크에서 파일을 읽거나 쓰는 것을 효율적으로 관리하기 위한 프로그램입니다. 디스크의 특성상 Sequential Access가 Random Access보다 훨씬 빠르기 때문에 읽기 작업과 쓰기 작업의 지역성을 높이는 형식으로 효율을 높일 수도 있고, dirty page들의 쓰기 순서도 조절해줄 수 있겠지요.
데이터베이스 파일은 위에서도 말했듯이 페이지들의 모음으로 구성됩니다. Collection of Pages라고 강의에선 표현합니다. Storage Manager는 파일을 구성하고 있는 페이지들에 어떤 읽기 연산과 쓰기 연산이 행해졌는지를 관리하며 페이지 내의 남은 공간이 얼마 있는지도 관리하게 됩니다. 이런 정보가 있어야 읽기/쓰기를 쉽게 할 수 있겠죠.
이제부턴 페이지가 어떤 것이고 어떻게 디스크에 저장되며, 페이지 안에 담기는 정보들은 그 안에 어떤 형식으로 저장되는지에 대한 내용입니다.
Pages
파일은 단순히 페이지의 모음이라고 했으니 이젠 페이지는 어떻게 구성될지 알아보죠. OS에서 쓰이는 페이지도 그렇듯이 페이지는 고정 길이입니다. 그 길이는 어떤 시스템이냐에 따라 다르게 정의되기도 합니다.
페이지는 어떤 정보를 가질 수 있을까요? 데이터베이스가 가져야 할 내용은 어떤 테이블의 메타 데이터, 실제 레코드들, 인덱스, 로그 등 어떤 정보도 가질 수 있습니다. 그렇다고 두 종류의 정보를 한 페이지 안에 담진 않고 하나의 페이지엔 한 종류의 정보만 담는 것이 일반적입니다.
DBMS 중 일부는 전체 페이지만 있어도 해당 페이지를 이해할 수 있도록 합니다. 이게 어떤 의미냐면 페이지 안에 해당 페이지 내부에 이 페이지에 어떤 내용이 담겨 있고 어떻게 해석하면 되는지에 대한 정보가 있어야 한다는 것입니다. 이와 같은 메타데이터가 다른 페이지에 담겨 있다고 할 때, 그런 페이지가 손상되었다면 다른 페이지를 읽을 수 없기 때문에 위와 같은 제한을 걸기도 합니다.
각 페이지는 유니크한 id를 가져서 이를 지정할 수도 있습니다. 정리해봅시다.
- DBMS Page
- 고정 길이(Fixed Length)를 가지며 그 길이는 시스템마다 다르게 정의되기도 합니다.
- 페이지 안에 담길 수 있는 정보는 정말 아무거나 다 가능합니다. 메타데이터, 레코드, 로그, 인덱스 뭐든 상관 없습니다. 다만, 일반적으로 하나의 페이지 안에는 한 종류의 정보만 저장합니다.
- 각 페이지는 유니크한 identifier를 가지고 있어서 어떤 페이지를 찾으면 그 페이지가 어떤 것인지 바로 알 수 있도록 합니다.
DBMS에는 여러 종류의 Page가 등장합니다. 디스크 자체의 Page가 있고 OS에서 사용하는 Page가 있으며, 마지막으로 위에서 언급한 DBMS가 사용하는 Page가 있습니다. 각 페이지의 크기는 어떤 시스템이냐에 의존합니다.
atomic한 연산이 중요하게 되는데 atomic write를 보장할 수 있는 단위는 디스크의 hardware page의 크기가 됩니다. 만약 DBMS의 페이지는 8KB인데 디스크의 페이지가 4KB라면 8KB의 쓰기 연산 중에서 4KB만 성공하고 4KB는 실패할 수도 있다는 뜻입니다. 이렇듯 DBMS의 페이지가 하드웨어의 페이지보다 크다면 페이지 단위의 atomic한 연산을 지원하기 위해서 추가적인 작업이 필요할 것입니다.
How to store pages?
데이터베이스 파일은 페이지로 구성되고 그 페이지는 어떤 정보를 담고 있는지 알아봤습니다. 이제 이 페이지들을 디스크에 어떤 방식으로 저장하고 찾아가는지 알아봅시다.
DBMS가 페이지를 디스크에 저장하는 여러가지 방법이 있지만 지금 알아볼 것은 heap file organization이라는 방식입니다. heap file이란 튜플들이 임의의 순서대로 저장되어 있는 페이지들의 unordered collection입니다.
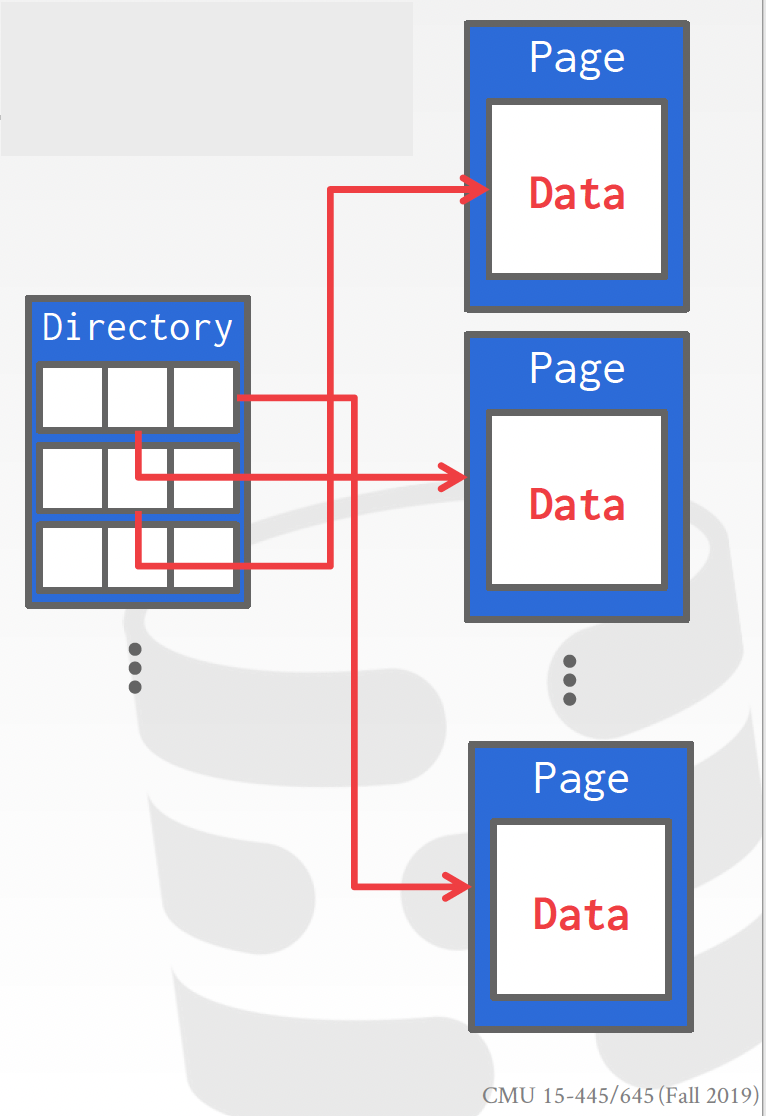
이 heap file을 저장하기 위해서 linked list나 page directory를 사용합니다.
linked list는 굉장히 비효율적인 방식으로 free page와 data page의 page id들을 각각 리스트 하나에 저장하고 필요할 때마다 해당 리스트를 순차검색합니다.
page directory란 각 페이지 id와 그 페이지의 주소를 기록해두는 페이지테이블과 같은 역할을 합니다. 접근하고 싶은 페이지의 id를 가지고 있으면 그 페이지가 디스크의 어디에 위치했는지를 알 수 있어요. 그리고 해당 페이지에 공간이 얼마나 남았는지도 같이 저장해둡니다. 그리고 이러한 정보들을 담은 page directory 또한 페이지에 담겨서 디스크에 저장될테니까 이에 대한 정보도 관리를 해줘야 할 것 입니다.
page directory 안에다 각 페이지의 free space도 기록을 해두기 때문에 data page에 쓰기 연산을 한 뒤에 page directory도 갱신을 해야하고 이는 항상 consistent 해야 합니다. 이러한 정보의 consistency 관리에도 신경을 써줘야겠죠.

Page Layout
지금까지 본 것은 페이지를 어떤 방식으로 저장해서 어떤 방식으로 찾아갈지에 대한 내용이었습니다. Linked List나 Page Directory 모두 우리가 찾고자 하는 페이지의 id를 알 때 그 페이지가 어디에 저장되어 있는지를 찾는 구조입니다.
이제 페이지의 내부는 어떻게 구성되는지 살펴보겠습니다. 페이지는 일단 header와 data 부분으로 나눠져 있다. 이 헤더에는 페이지의 메타데이터가 들어있다. 메타 데이터로 쓸모가 있을 정보들은 페이지의 크기, 해당 페이지의 dirty 여부를 체크해줄 checksum, 이 페이지 구조를 사용하는 DBMS의 버전, 누가 어떤 트랜잭션이 행해졌는지, 압축되어 있다면 어떤 방식으로 압축되었는지와 같은 것들이다.

위에서 언급했던 self-contained page라면 해당 페이지의 정보를 어떻게 해석해야 되는지에 대한 정보 또한 헤더에 같이 담고 있을 것이다.
이제 data 부분에 어떻게 저장할지를 알아야 한다. 페이지 안에는 인덱스든 로그든 레코드든 어떤 정보도 저장될 수 있다고 했다. 그러나, 여기서 집중해볼 것은 tuple, 레코드들만 저장한다고 생각하도록 하겠다.
tuple을 저장하는 방법에는 여러가지가 있겠지만 tuple-oriented와 log-structured의 두 방식을 보자.
Tuple oriented
이 방식은 페이지 내부에 튜플 자체를 저장하는 것을 의미한다. 그러면 튜플들을 어떤 방식으로 저장할까?
제일 간단한 것은 헤더에 현재 저장되어 있는 튜플의 수를 저장하고 새로운 튜플을 저장할 때는 그냥 현재 저장되어 있는 튜플의 제일 끝에 넣는 방식이다.
이 방식은 간단해서 좋지만 바로 여러 방면에서 문제가 발생한다. 데이터를 저장하다가 중간에 존재하는 튜플이 삭제되면 그냥 끝에 새로운 튜플을 넣는 방식으론 공간이 낭비된다. 아니면 전부 해당 튜플 이후 전부를 당겨서 저장해서 공간을 절약해야 한다.
이 정도 문제야 뭐 헤더에 현재 비어 있는 공간 위치를 저장해서 해결한다 치자. 만약 튜플이 고정 길이가 아니라 가변 길이라면? 중간중간에 비어 있는 공간에 들어가는 튜플이 삽입되지 않는다면 그 공간은 계속 낭비되고 있을 것이다.
다음 방식은 Slotted Page이다. 튜플을 하나 저장할 때마다 슬롯을 하나 늘리고 튜플을 저장한다. 그리고 해당 슬롯에는 슬롯에 해당하는 튜플의 시작 주소를 저장한다. 슬롯들이 저장되는 slot array는 페이지의 시작부분에서 시작하고 데이터는 페이지의 끝에서부터 저장하기 시작한다.


이 방식은 가변 길이여도 문제가 없다. 그러나, 튜플들이 차례로 쌓였을 때 중간의 튜플을 삭제하면 그 공간이 비게 되는 것은 여전한 문제로 남아있다. 그래서 적절하게 중간 공간들을 압축해줄 필요는 여전히 있다.
이제 DBMS는 특정 릴레이션의 특정 튜플을 원한다면 그 레코드가 어떤 페이지의 몇 번째 slot에 있는지를 저장해두면 page directory에게 말해서 그 레코드를 가지고 올 수 있게 된다. 이런 정보가 postgresql에는 CTID라는 내부 값으로 정의되어 있고 sqlite과 오라클에서는 ROWID로 정의되어 있다.
Log-structured
튜플 전체를 저장하기보단 튜플이 어떻게 만들어지고 수정되었는지에 관한 기록만 저장해두는 방식이 log-structured 방식이다. 이 방식의 가장 큰 장점은 쓰기 연산을 할 때 빠르다는 점이다. 디스크는 random access 보다 sequential access가 훨씬 빠르다.
튜플의 주소를 찾아서 접근하고 수정하고 삽입하는 것보단 그냥 로그 뭉치를 던져버리면 빠르다. 문제는 읽기다. 로그의 끝 부분부터 필요한 부분까지 전부 읽어야 한다.
읽기 시에 발생하는 오버헤드를 줄이기 위해서 로그의 인덱스를 만들거나 주기적으로 로그를 압축해서 정리해줄 수 있다.
Tuple Layout
페이지 안에 튜플을 어떻게 저장할지를 알았다. 그러면 튜플의 내부는 또 어떻게 저장될까? 튜플 또한 메타 데이터를 위한 헤더가 있고 raw data를 저장한다. 중요한 메타데이터로는 특정 속성이 null인지를 나타내는 bitmap이 있다.
관계형 DB에서는 튜플의 스키마를 튜플 헤더에 저장할 필요는 없다고 한다. 왜냐면 튜플마다 다른 스키마를 가지는 것이 아니기 때문이다.
그리고 일반적으로 DBMS가 정의한 스키마의 속성 순서대로 속성을 저장한다.
정리
굉장히 긴 내용이었으니 정리를 해봅시다.
데이터베이스는 디스크 위에 저장되고 디스크는 느리고 데이터베이스 파일은 정말 크다. 그래서 메모리에 이를 올리기 위해서는 파일들을 적절히 작은 단위로 나눠서 저장할 필요가 있었고 DBMS에서 파일을 나누는 단위를 페이지라고 부른다.
이제 데이터베이스 파일은 페이지로 나눠져서 디스크 위에 저장된다. 이 페이지는 시스템마다 크기가 다르지만 고정 길이며 어떠한 정보든 저장될 수 있다. DBMS에서는 각 페이지에 unique page id를 부여한다.
데이터베이스 파일은 굉장히 크기 때문에 많은 수의 페이지를 가진다. 그래서 디스크 위에 있는 페이지들을 찾아가기 위해서 추가적으로 관리가 필요하다. 이 방식으로는 heap file이라는 것을 봤고 이 heap file이라는 것은 일반적으로 page directory라는 방식으로 나타낸다.
page directory는 page id 별로 디스크 상의 주소와 해당 페이지의 남은 공간을 기록해둬서 읽기/쓰기 연산을 할 때 바로 원하는 페이지에 접근할 수 있도록 해줍니다.
파일들은 페이지로 구성되어 있고 페이지들을 찾아가기 위한 방법도 봤으니 페이지 내부를 봅시다.
페이지 내부는 페이지의 크기, dirty여부, 트랜잭션 여부 등의 메타데이터를 저장하는 헤더가 있습니다. 실제 튜플을 저장할 땐 보통 slotted page 방식을 사용합니다.
페이지의 시작 부분에는 slot array가 있고 끝 부분에는 튜플 데이터가 있어서 튜플을 추가하면 튜플은 끝에서부터 차례차례 저장되고 slot array는 시작 부분에서 자라납니다. 그리고 slot array의 slot에는 튜플들의 시작 주소가 저장되어 있습니다.
튜플을 저장하는 다른 방법으로는 log-structured 방식이 있습니다. 이 방식은 튜플 전체를 저장하지 말고 튜플의 변화에 관한 기록만 저장해둡니다. 이렇게 함으로 쓰기 연산이 굉장히 빨라집니다. 문제는 읽기인데 저장된 로그에서 원하는 튜플의 정보를 복원해야 되기 때문입니다.
읽기의 오버헤드를 줄이기 위해서 튜플에 대해서 로그의 인덱스를 만들거나 주기적으로 로그를 압축하기도 합니다.
튜플을 저장하는 방식을 봤으니 튜플 내부를 봐야죠. 튜플 또한 속성들의 null 여부와 같은 메타데이터를 헤더에 갖고 있습니다. 관계형 DB에서는 일반적으로 한 페이지 내부의 튜플들은 같은 스키마를 가지고 있기에 헤더에 메타데이터를 들고 있을 필요는 없습니다. JSON-based DB의 경우는 튜플마다 스키마가 달라질 수 있기 때문에 필요할 수도 있습니다. 그리고 속성들이 저장되는 순서는 보통 스키마를 정의한 순서와 동일합니다.
'DB 공부' 카테고리의 다른 글
| Buffer Pool Manager - 1 (1) | 2021.06.23 |
|---|---|
| DBMS는 저장소를 어떻게 관리하는가? - 2 (2) | 2021.06.08 |
| SQL에서 NULL과의 연산 (0) | 2021.05.21 |
| SQL 쿼리 연습문제 2 (0) | 2021.05.18 |
| SQL 쿼리 연습문제 (0) | 2021.05.14 |


