Data Representation
데이터베이스 파일은 페이지들로 구성되고 그 페이지가 어떻게 저장되는지 또 어떻게 찾아가는지를 알았습니다.
이제 튜플의 데이터들이 어떻게 표현되는지 볼 차례입니다. 디스크에 저장되어 있는 것은 크게 봤을 때 그저 바이너리일 뿐입니다. 이를 해석하는 것은 DBMS의 일입니다.
DBMS는 튜플 내부에 대한 정보를 어떻게 해석할지를 알아야 하는데 이 정보는 우리가 스키마라고 얘기하는 것과 상통하는 부분입니다. 그리고 이런 정보를 catalog에 저장해둡니다.
튜플 내부에 저장되는 값들의 종류를 몇가지 살펴봅시다.

Integer는 우리가 흔히 다루는 자료형 중 하나로 INTEGER, BIGINT, SMALLINT, TINYINT 같은 자료형이 있으며 C/C++의 native type을 그대로 씁니다. 이 자료형은 고정 길이입니다.
Variable-Precision Number도 역시 수를 나타내는 자료형입니다. 그 중에서 실수를 나타내기 위한 자료형인데 FLOAT, REAL/DOUBLE과 같은 이름이 있습니다. 이 또한 C/C++의 native type을 그대로 쓰는 경우가 많습니다. 그리고 이 자료형 또한 고정길이입니다. 대부분의 CPU는 C/C++의 native type을 쓰는 실수 연산을 instruction으로 들고 있기 때문에 임의 정밀도 실수 연산보다 매우 빠릅니다. 그러나 모두가 알듯이 이 실수형은 오차가 큽니다.
Fixed-Precision Numbers는 실수 오차를 허용할 수 없는 상황일 때 사용되는 자료형입니다. NUMERIC, DECIMAL과 같은 이름으로 사용되곤 합니다. 보통 메타데이터와 함께 가변 길이의 binary로 저장됩니다. 물론 이는 CPU에서 instruction으로 제공되는 자료형이 아니기 때문에 DBMS에서 직접 연산을 하고 저장하고 읽는 방식을 구현해줘야 합니다.
Fixed-Precision Numbers는 가변 길이인 속성입니다. 가변 길이인 속성들은 보통 뭐가 있냐면 VARCHAR, VARBINARY, TEXT, BLOB 같은 이름을 가진 타입들이 있습니다.
거시적인 관점에서 보면 가변 길이의 자료형들은 디스크 위에서 그냥 ByteArray입니다. 튜플에 저장할 때는 이 ByteArray의 길이와 시작주소 같은 메타데이터를 함께 저장해서 읽어올 수 있도록 합니다.
가변 길이이기 때문에 이런 속성값들이 너무 커질 수도 있습니다. 이를 막기 위해 일반적으로 DBMS들은 튜플의 크기를 페이지 하나의 크기보다 클 수 없게 합니다. 만약 저장해야 된다고 하면 데이터베이스의 다른 페이지(overflow page)에 저장해두고 그 페이지의 포인터를 저장해둡니다. 혹은 따로 파일로 저장해두고 해당 파일의 주소를 저장하기도 합니다. 이렇게 파일로 저장하는 경우를 BLOB이라고 부릅니다.
overflow page를 따로 둬서 크기가 큰 속성을 저장하는 이유 중 하나로 쓰기 작업 도중에 실패하게 되면 그 복구를 쉽게 하기 위함입니다. 그리고 이렇게 따로 저장하게 되면 읽기 작업의 성능이 올라갈 수도 있습니다.


System Catalogs
각 테이블마다 저장하게 되는 튜플들의 형태가 다르기 때문에 디스크에 저장된 튜플들을 어떻게 해석할지를 기록해둬야 합니다. 특정 테이블의 튜플이 어떻게 생긴 애인지를 나타내는 메타데이터를 system catalog라고 부릅니다. 이런 system catalog는 INFORMATION_SCHEMA 테이블에 내부적으로 저장해둡니다. sqlite에는 이런 테이블 명 말고 sqlite_master라는 테이블에 저장되어 있습니다.

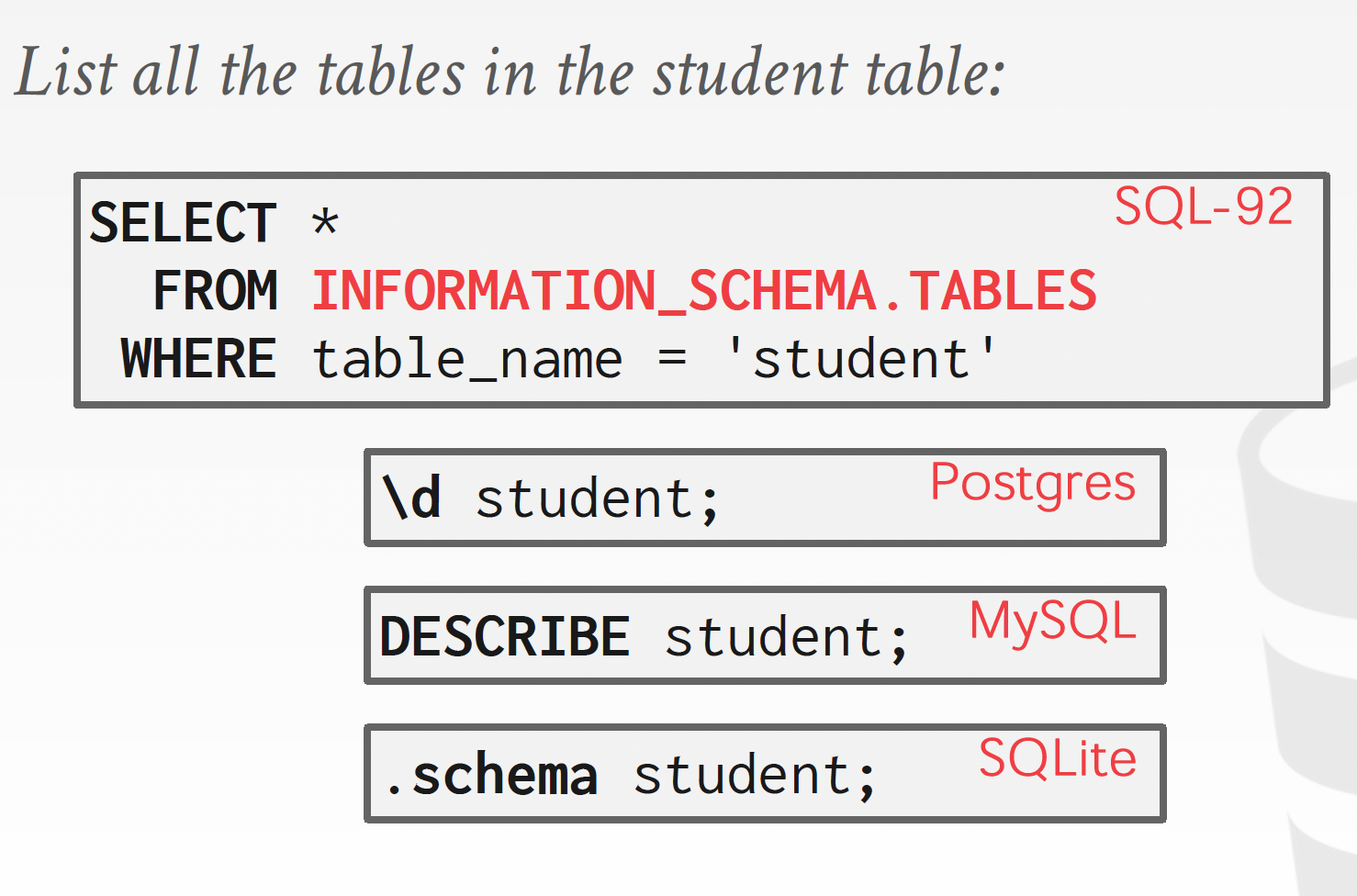
이런 system catalog를 토대로 디스크에 저장된 bytearray를 읽게 됩니다. 방식은 정말 단순하게 switch문으로 일일이 체크할 수도 있고 아니면 JIT 컴파일과 같이 미리 최적화된 어셈블리를 만들어서 읽을 수도 있고 그럽니다.
Data Storage Models
데이터베이스를 활용하는 작업(workload)은 크게 두가지로 볼 수 있습니다. OLTP와 OLAP 입니다.
On-line Transaction Processing(OLTP)
OLTP는 외부의 적은 데이터를 데이터베이스에 추가하거나 수정하는 작업들이 주로 이루어지는 workload를 말합니다. 데이터베이스에서 적은 양의 데이터를 읽고 수정하는 일이 굉장히 많은 종류입니다.
예시로는 아마존을 생각해봅시다. 아마존의 프론트에서는 굉장히 많은 유저가 물품을 구매할 것입니다. 엄청난 수의 유저가 장바구니에 물품을 넣고 구매를 진행하고 구매가 진행되면 유저의 계정도 업데이트해야 될 것입니다.
그런데 유저 한 명 한 명의 입장에서 수행되는 일들은 종류가 몇 개 없고 데이터베이스에 영향을 끼치는 데이터의 양이 적습니다. 단순히 유저 본인의 계정정보와 장바구니 정도만 업데이트되죠.
실행되는 쿼리 자체는 데이터베이스 내부에서 정말 적은 부분에 영향을 끼치는 간단한 쿼리들이지만 그 쿼리의 수 자체가 굉장히 많은 형식의 작업입니다.
아래의 테이블은 위키피디아의 간소화된 DB테이블 정도로 생각해주세요.


위 테이블에 대해서 그림과 같은 쿼리들을 굉장히 자주 수행하게 되는 workload라면 OLTP라고 생각할 수 있습니다.
첫번째 쿼리는 특정 페이지의 가장 최근 revision을 찾는 쿼리입니다. 원하는 튜플이 하나에요. 두번째는 특정 유저의 최근 로그인 기록을 갱신하는 쿼리문입니다. 이것도 특정 유저의 계정 튜플 하나만 필요하고, 세번째는 revision에 튜플 하나를 추가합니다.
이런 식으로 적은 양의 튜플을 원하는 비교적 간단한 쿼리들을 굉장한 수로 처리해야 되는 workload를 OLTP라고 합니다.
On-line Analytical Processing
OLAP는 OLTP와는 대비되게 쿼리 한 번이 복잡하며 데이터베이스 내부에서 많은 수의 튜플을 읽어들이는 쿼리를 수행하게 되는 workload입니다.
또 중요한 차이점은 이 workload에서는 쓰기 연산이 거의 일어나지 않고 읽기 연산이 대부분이라는 것입니다. 주로 OLTP에서 모은 데이터들에서 많이 읽어낸다는 것입니다.
예를 들자면 아마존에서 최근 한달간 각 지역별로 가장 많이 구매된 품목 10개를 뽑는 쿼리 같은 것입니다.
이런 식으로 분석을 위해 수행하게 되는 쿼리들을 주로 사용하는 workload를 OLAP라고 부릅니다.

위키피디아 테이블에선 위와 같이 최근 로그인을 월별로 뽑는 쿼리가 예시가 될 수 있겠지요.
Data Storage Model
지금까지는 기본적으로 튜플 하나를 저장할 때 모든 attribute를 하나의 페이지에 저장하는 방식을 전제로 얘기했습니다. 그러나 관계형 모델은 이 저장방식에 대해서 제한을 취하지 않습니다.
그래서 어떤 workload냐에 따라서 어떤 저장 방식이 더 효율적일 수도 있어서 그에 맞춰 바꿀 수도 있습니다.
N-ary Storage Model(aka row storage)
지금까지 말해왔던 방식은 row storage, N-ary Storage Model이라고 부릅니다. 튜플의 모든 속성을 한 페이지 안에 연속적으로 저장하는 방식입니다.
OLTP에선 하나의 튜플을 삽입/갱신하는 쿼리가 굉장히 많이 처리되기 때문에 이와 같은 저장방식이 잘 맞습니다.

OLTP에선 아래와 같은 쿼리를 굉장히 많이 처리할 것입니다.
SELECT * FROM useract
WHERE userName = ?
AND userPass = ?이런 쿼리가 들어오게 되면 DBMS는 해당 테이블의 인덱스로 가서 튜플 위치를 찾고 딱 이에 해당되는 튜플 몇가지만 디스크에서 찾아오죠. 튜플 전체를 하나의 페이지 안에 연속적으로 저장하게 되면 디스크 I/O 횟수가 딱 찾고자 하는 튜플 정도만 발생할 것이기 때문에 위 작업에는 굉장히 잘 맞습니다.

그러나 이러한 저장방식은 OLAP와는 잘 맞지 않습니다. 아래 쿼리를 생각해봅시다.
SELECT COUNT(U.lastLogin),
EXTRACT(month from U.lastLogin) AS month
FROM useract AS U
WHERE U.hostname LIKE "%.gov"
GROUP BY EXTRACT(month from U.lastLogin)이 쿼리에서 필요한 속성은 hostname과 lastLogin입니다. 그리고 봐야할 튜플들은 useract 테이블의 전체 튜플이죠.
NSM방식으로 튜플이 저장되어 있다면 단 두가지만 필요한데 튜플 전체를 읽어야만 합니다. 왜냐면 튜플들은 디스크 상에 저장되어 있으니까요.
단순한 계산이지만 모든 속성의 크기가 같다면 실제 필요한 데이터보다 2배 넘는 데이터를 읽어들여야 하고 이는 곧바로 디스크 I/O가 두 배 늘어난다고 생각할 수 있습니다.

정리해봅시다. NSM은 튜플 하나를 연속적인 공간 위에 저장하는 방식을 말합니다.
장점으로는 1. 삽입, 갱신이 빠르다. 2. 튜플 전체를 원하는 쿼리에선 빠르다.
단점으로는 많은 수의 튜플들을 읽을 때 속성의 일부분을 원한다면 매우 비효율적이다.
Workload로 구분하자면 OLTP에는 잘 맞지만 OLAP에는 잘 맞지 않습니다. 그리고 OLTP나 OLAP나 둘 다 굉장히 널리 사용되는 workload기 때문에 이를 위해서 다른 저장방식도 생각해냅니다.
Workload로 구분하자면 OLTP에는 잘 맞지만 OLAP에는 잘 맞지 않습니다. 그리고 OLTP나 OLAP나 둘 다 굉장히 널리 사용되는 workload기 때문에 이를 위해서 다른 저장방식이 있습니다.
Decomposition Storage Model (a.k.a column store)
NSM에서는 튜플 전체를 페이지 안에 연속적으로 저장했다면 DSM(Decomposition Storage Model)은 테이블의 하나의 속성을 연속적으로 저장하는 방식입니다. column store라고도 부릅니다.
테이블의 일부 속성을 많이 읽어들이게 되는 OLAP에는 NSM보다 DSM이 적합합니다.

방금전에 OLAP의 예시로 들었던 쿼리를 다시 살펴봅시다.
SELECT COUNT(U.lastLogin),
EXTRACT(month from U.lastLogin) AS month
FROM useract AS U
WHERE U.hostname LIKE "%.gov"
GROUP BY EXTRACT(month from U.lastLogin)DSM 방식으로 데이터베이스가 저장되어 있다면 hostname 속성만 저장되어 있는 페이지를 읽은 뒤에 lastLogin 속성이 저장된 페이지만 읽으면 된다.
그리고 이런 방식으로 저장할 시에 동일한 데이터가 많이 저장되어 있다면 이를 압축해서 저장하는 것도 훨씬 쉽게 만들어주기 때문에 저장 공간 관리에도 도움이 될 수 있다.
당연한 얘기겠지만 적은 수의 튜플을 읽어들이는 쿼리를 처리할 때는 정말 느리다. 한 번의 디스크 I/O면 될 것은 속성 갯수만큼 접근해야될테니 말이다.
DSM에는 해결해야 될 문제가 있다. 위 쿼리에서는 조건문에 맞는 hostname 속성을 찾았다고 치자. 그에 상응하는 lastLogin 속성을 다른 페이지 안에서 찾아야 한다. 이런 식의 접근을 어떤 방식으로 수행해야 되냐는 것이다.
두 가지 접근 방식이 존재한다.
하나는 Fixed-length Offset이다. 대부분의 DBMS는 이 방식을 이용한다.
하나의 테이블 내에서 하나의 속성은 전부 고정 길이로 저장하는 것이다. 이렇게 저장을 하면 우리가 찾은 hostname의 offset 이 x라고 하면 이에 상응하는 lastLogin의 offset 또한 x가 된다. 따라서 바로 접근이 가능하다.
물론 hostname의 길이는 100이고 lastLogin의 길이는 10이어도 어차피 각 속성은 고정길이이기 때문에 한 쪽의 offset을 아니까 다른 쪽의 주소도 바로 알 수 있게 된다.
다른 접근 방식은 Embedded Tuple Ids다. 이름에서 유추할 수 있듯이 그냥 튜플의 ID와 함께 속성을 저장하는 것이다. Andy 말로는 아마 아무도 이 방식은 사용 안 할거 같다고 한다.
DSM의 장점과 단점을 간단히 정리해보자.
장점으로는 1. 쿼리가 필요한 데이터만을 읽어들이는 게 가능하기 때문에 디스크 I/O가 줄어든다. 2. 데이터의 압축을 진행하기가 쉽다.
단점으로는 OLTP 방식에서 자주 쓰이는 point query는 굉장히 느리다.
What people do?
NSM은 OLTP에, DSM은 OLAP에 강한 저장방식입니다. 둘을 섞는 방식을 시도해봤지만 두 가지 다른 저장방식이을 지원하는 DBMS를 만드는 것은 사실상 DBMS를 두 개 만드는 것과 크게 다를 것이 없습니다.
너무 많은 품이 들어가야 해요. 하지만 데이터는 너무 중요하고 이를 이용해서 분석도 진행하고 싶습니다. 그럼 사람들은 어떻게 이를 관리할까요?
그냥 같은 내용을 저장하는 데이터베이스를 두 개 만들까요? 만약 데이터베이스가 1 페타바이트쯤 된다면 이건 좀 비현실적이겠죠.
사람들이 주로 취하는 방식 하나는, 프론트엔드용의 OLTP 시스템을 하나 만듭니다. 여기에 데이터가 점점 쌓이겠죠.
데이터가 쌓임에 따라서 백엔드의 큰 데이터베이스로 프론트에서 백으로 옮겨갑니다. 그리고 이 백엔드에서 OLAP를 수행합니다.
OLTP에서 더 이상 쓰지 않는 좀 오래된 데이터들을 백엔드로 옮겨서 프론트의 OLTP는 빠릿빠릿하게 움직이도록 하고 백에서 OLAP를 빠릿하게 수행할 수 있도록 시스템을 구성합니다.
eBay에서는 프론트의 OLTP 사이드에서는 최근 90일의 데이터만 저장해두고 90일 이전의 데이터들은 백엔드로 보내서 프론트를 빠르게 유지하면서 데이터 분석도 백엔드에서 빠르게 할 수 있도록 한다고 합니다.
그림으로 나타내보면 아래와 같습니다.

프론트에서 OLTP를 통해 데이터를 쌓다가 백엔드로 보냅니다. 이 보내는 과정을 ETL이라고 줄여서 부르기도 합니다.
그리고 복잡한 쿼리는 백엔드에서 처리하고 다시 프론트로 보내지요. 이 때 프론트에서 둘 다를 처리할 수 있도록 하자는 시스템을 HTAP이라고 부르기도 한답니다.
보통 프론트엔드는 MySQL이든 MongoDB든 오라클이든 Postgresql이든 이런 DBMS를 사용하고 백엔드는 스파크나 하둡 같은 것을 사용합니다.
정리
먼저 튜플의 속성들을 어떤 방식으로 나타내고 저장하는지를 알아봤습니다. 그리고 튜플들에 어떤 속성이 있어서 어떻게 해석하면 되는지를 담는 메타데이터를 system catalog라고 부릅니다.
일반적으로 DBMS를 사용할 때 주요 workload가 두 종류 있는데 각각 On-line Transaction Processing(OLTP), On-line Analytical Processing(OLAP)이라고 부릅니다.
OLTP는 일반적으로 적은 수의 튜플을 쓰고 갱신하는 쿼리가 자주 사용되는 workload입니다.
OLAP는 많은 수의 튜플들에서 일부 속성을 읽는 쿼리가 자주 사용되는 workload입니다.
튜플을 페이지 안에 하나의 튜플에 속하는 속성 전체를 연속적으로 저장하는 방식을 N-ary Storage Model(NSM) 이라고 합니다. 이 저장방식은 OLTP에 적합하고 OLAP에는 적합하지 못합니다.
튜플의 속성들을 속성별로 연속적으로 저장하는 방식은 Decomposition Storage Model(DSM)이라고 합니다. 이 저장방식은 OLAP에 적합한 방식이었습니다.
각 저장 방식이 적합한 workload가 다르기 때문에 OLTP에서 축적된 데이터를 OLAP에서 사용하기 위해서 일정 양이 쌓이게 되면 필요한 정보 외에는 OLAP에 적합한 DBMS Instance 쪽으로 옮기도록 합니다.
'DB 공부' 카테고리의 다른 글
| Buffer Pool Manager - 2 (0) | 2021.06.25 |
|---|---|
| Buffer Pool Manager - 1 (1) | 2021.06.23 |
| DBMS는 저장소를 어떻게 관리하는가? (0) | 2021.06.02 |
| SQL에서 NULL과의 연산 (0) | 2021.05.21 |
| SQL 쿼리 연습문제 2 (0) | 2021.05.18 |



