1. Introduction
본 논문은 2018년 NIPS에서 발표된 Transfer Learning from Speaker Verfication to Multispeaker Text-To-Speech Synthesis입니다. 공식은 아니지만 유명한 구현체는 여기에 있습니다.
본 논문의 목표는 데이터를 적게 사용하며 많은 화자의 자연스러운 목소리를 만들 수 있는 TTS 시스템입니다. 특히, 훈련 도중에 모델이 보지 못했던 화자의 목소리를 추가적인 파라미터의 변경 없이 만들어 내는 것이 목표입니다. (Zero-shot Setting)
이를 위해 제안하는 방법은 Speaker Modeling을 담당하는 모듈을 분리하여 훈련시킨 뒤에 대상 화자의 목소리를 해당 모듈에 입력으로 넣어 출력으로 Speaker Embedding을 만듭니다. 이 임베딩 벡터를 음성합성 모델의 훈련에 사용합니다.
기존의 방법들과의 주요 차이점은 두 가지 입니다.
첫째로는 Deep Voice와 같은 시스템에서는 Multi Speaker TTS를 위해서 lookup 방식의 임베딩을 사용했지만 본 논문에서 제안하는 방법은 lookup 방식이 아니라 Encoding Network를 사용한다는 점입니다.
두번째로는 이전에 encoding network를 사용했던 모델들과 달리 합성기의 훈련과 인코더의 훈련을 완전히 분리시켜서 진행했다는 점입니다.
논문의 키포인트는 Speaker Encoder를 다른 태스크에 대해서 훈련시킨 뒤 전이 학습을 진행하여 좋은 결과를 얻을 수 있었다는 것입니다.
2. Multispeaker speech synthesis model
2-0. 모델의 전체 구조
제안한 모델은 크게 1. Speaker Encoder, 2. Synthesizer, 3. Vocoder의 세가지 모듈로 이루어져 있습니다.
음성합성을 담당하는 모델은 Tacotron2를 베이스로 하며 합성기의 인코더 출력에다 임베딩 벡터를 붙여서(concat) 디코더의 입력으로 사용합니다. 이를 토대로 합성기는 멜 스펙트로그램을 생성하며 보코더는 멜 스펙트로그램을 실제 음성으로 바꿔줍니다.

2-1. Speaker Encoder
Speaker Encoder는 음성이 주어지면 화자의 특성을 잘 나타낼 수 있고 서로 다른 화자끼리는 충분히 구분할 수 있어야 합니다. 거기다가 짧은 길이의 음성이 주어지면 음성의 내용과 포함된 잡음의 상관없이 이를 달성할 수 있어야 합니다. 따라서, 논문에서는 Text-Independent Speaker Verification을 위해 훈련한 모델을 Speaker Encoder로 채택했습니다.
이 네트워크는 임의의 음성의 멜 스펙트로그램을 d-vector라는 고정된 크기의 임베딩 벡터로 변환시킵니다. 훈련은 Speaker Verification을 위해 설계된 GE2E loss를 최적화하며 훈련되었습니다. 말로 전달하자면 같은 화자의 음성끼리는 코사인 유사도가 높게 나오도록, 서로 다른 화자의 음성은 임베딩 공간에서 멀게 나오도록 훈련했습니다.
모델의 마지막 레이어의 출력에 L2 정규화를 취한 것을 임베딩벡터로 사용합니다. 추론 시에는 입력 음성을 50%씩 겹치게 800ms 단위로 쪼개 각 프레임 별로 임베딩 벡터를 만든 뒤 평균을 취한 것을 다시 정규화한 것을 최종 임베딩 벡터로 사용합니다.
2-2. Synthesizer
Tacotron 2를 베이스로 하는 multi speaker 모델인 deep voice 2와 비슷한 모델을 사용했습니다. 합성기는 텍스트 문자열을 입력으로 받고 멜 스펙트로그램을 출력하는 인코더-디코더 모델입니다. 여기서 인코더의 출력에 화자의 임베딩 벡터를 concatenate하여 디코더의 입력으로 사용합니다.
훈련 데이터는 음성과 음성에 해당하는 text로 이루어져 있는데 text는 phoneme으로 변환한 뒤에 사용했습니다.
합성기는 이미 훈련된 Speaker Encoder를 사용하여 훈련시켰는데 인코더는 추가로 학습을 하지 않도록 했습니다. 타코트론 2를 훈련할 때 추가로 L1 loss를 augment했다고 합니다.
2-3. Vocoder
타코트론 2를 제시한 논문에서 사용한 WaveNet과 동일한 구조, 동일한 훈련 방식을 채택했습니다.
2-4 Inference and Zero-shot speaker adaptation
추론 시에는 수 초 길이의 만들고자 하는 화자의 음성을 화자 인코더에 입력으로 주고 합성기에는 만들고자 하는 텍스트 문자열을 입력으로 넣습니다. 아래 그림에서 왼쪽은 만들고자 하는 화자의 음성, 오른쪽은 "This is a big red apple"이라는 문장으로 합성한 음성의 멜 스펙트로그램입니다.
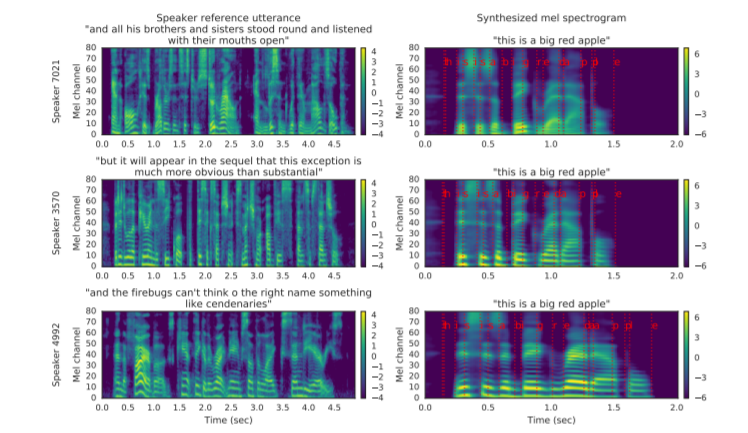
제일 위의 화자는 남성이며, 그 아래의 둘은 화자가 여성입니다. 보시면 합성된 음성 중 남성의 것이 여성의 것보다 더 낮은 기본 주파수를 가지고 있는 것을 확인할 수 있습니다. 이는 남성의 멜 스펙트로그램에서 가로 줄무늬 모양이 아래쪽에 위치한 것을 통해 알 수 있습니다.
3. 실험
3-0. 실험 데이터셋과 세팅
Synthesizer와 Vocoder 두 모듈의 훈련에는 VCTK, LibriSpeech 두 데이터셋을 사용했습니다. 각 데이터셋을 동시에 사용해 하나를 훈련하지 않고 데이터셋당 하나의 모델을 독립적으로 훈련시켰습니다.
VCTK에는 24K로 다운샘플링하는 것과 음성의 앞 뒤로 침묵을 없애는 전처리를 수행했습니다.
Librispeech는 음성이 길었기 때문에 적절히 자르고 침묵을 없애는 과정을 수행했습니다. 또한, 비교적 잡음이 섞인 데이터셋이었기 때문에 음성이 아닌 스펙트로그램에만 simple spectral substraction을 수행해서 잡음을 제거하는 과정을 수행했습니다. 이 과정은 스펙트로그램을 만드는 합성기의 ground truth에만 적용했습니다.
합성기의 입력으로는 text를 phoneme으로 바꿔서 사용했습니다. Vocoder의 훈련에는 VCTK 모델은 ground truth의 스펙트로그램을, Librispeech는 합성기의 출력을 보코더의 입력으로 사용했습니다.
제일 중요한 Speaker Encoder는 18000명의 화자의 3600만개의 발화에 대해서 학습했습니다. 발화 길이의 중앙값은 3.9초였습니다. 해당 데이터셋은 script없이 음성과 화자 ID만 존재하는 데이터셋입니다.
모델의 평가는 MOS 평가를 사용했으며 Absolute Category Rating을 사용했습니다. 이는 1점부터 5점까지 0.5점 단위로 나눈 평가 체계입니다. 이를 이용해서 생성된 음성의 자연스러움, 그리고 만들고자 했던 화자와의 유사도를 평가했습니다.
베이스라인으로는 비슷한 모델 구조이지만 훈련 데이터에만 존재하는 화자들의 lookup을 사용하는 Multispeaker speech synthesis 모델을 사용했습니다.
3-1. Speech Naturalness

생성된 음성의 자연스러움을 평가한 결과입니다. 생성된 음성은 훈련 중에 등장하지 않은 문장 100개를 골라서 만들어졌으며, VCTK에서는 seen, unseen 각각 11명씩, Librispeech에서는 각각 10명씩 화자를 선정하여 평가를 진행했습니다. Reference audio는 5초 길이의 각 화자의 발화를 사용했습니다.
Seen Speaker에 대한 결과는 베이스라인과 비슷하게 나왔습니다. Librispeech로 학습한 모델이 조금 더 안좋은데 이는 transcription에 문장 부호가 없다는 것과 비교적 noisy하다는 점에서 기인한 것으로 보입니다.
눈여겨 볼 점은 unseen speaker에 대한 결과가 seen speaker에 대한 결과보다 더 자연스럽다는 점입니다. 해당 결와에 대해서는 reference audio를 임의로 정한 것을 원인으로 짚었습니다. 생성된 음성은 화자에 대한 정보뿐만 아니라 reference로 주어진 발화의 운율도 따라하는 경향을 보였고 이는 다양한 운율을 지닌 Librispeech에 대해서 훈련된 모델에서 더 두드러졌습니다. 따라서, reference audio가 독특한 운율을 가졌을 경우에 자연스러움에 있어서 많은 차이를 보일 수 있다고 해석할 수 있습니다.
3-2. Speaker SImilarity

Ground truth의 평가는 같은 화자의 서로 다른 발화를 들려주고 어느정도 비슷한지 평가하는 방식으로 이루어졌습니다. 모델의 평가는 ground truth 음성을 reference로 사용하여 음성을 생성하고 만들어진 음성과 reference 음성의 비교로 이루어졌습니다. 평가 시에는 내용, 문법, 음질에 신경쓰지 않고 두 화자가 같은지에 대해서만 집중해달라는 문구와 같이 이루어졌습니다.
VCTK로 훈련된 모델은 Seen Speaker에 대해서 굉장히 훌륭한 결과를 보여주는 반면에 Librispeech는 굉장히 떨어지는데 이에 대해서는 데이터셋의 차이로 보인다고 말합니다. librispeech의 경우 화자가 책을 읽어주는 것이기 때문에 하나의 화자가 목소리를 바꿔서 내는 경우도 많고(Speaker Varation) 노이즈가 섞여 있어서 그런 것으로 보인다고 합니다.
Unseen Speaker에 대한 결과는 어느정도 모방이 잘 일어난다고 할 수 있습니다. 성별, 높낮이, 속도는 어느정도 모방하지만 화자의 특징적인 운율은 제대로 모방하지 못하고 있다고 볼 수 있습니다. 또한 encoder가 전부 북미 영어를 쓰는 화자로만 학습되었지만 평가시에 억양은 무시해달라고 하지 않았기 떄문에 이런 것이 반영된 결과로 보입니다.
서로 다른 데이터 셋에 대해서 similarity를 시험해봤을 때 굉장히 낮은 점수를 보였는데 특이한 점은 librispeech 모델이 더 높은 점수를 보였다는 것이다. 이는 데이터셋에 포함된 화자 수가 libri쪽이 더 많아서인 것으로 보입니다. 이를 통해 더 좋은 일반화 성능을 위해서는 합성기 또한 많은 수의 화자에 대해서 학습이 필요한 것으로 보입니다.
3-3. Speaker Verification

생성된 음성과 reference 음성 사이에 유사도를 정량적으로 측정하기 위해서 speaker encoder를 합성기에 사용한 것과는 다른 데이터셋을 사용하여 학습 시킨 뒤 speaker verification을 수행했습니다. 그 결과로 합성기의 학습에 사용된 화자수가 더 많은 Librispeech 모델이 VCTK 모델보다 훨씬 더 높은 성능을 보였습니다. 앞선 실험에서 Librispeech 모델이 서로 다른 데이터셋에 대해서 유사도가 더 높은 음성을 생성했던 결과와 일맥상통합니다.
또한, Librispeech에서 뽑은 10명의 실제 화자의 음성과 이를 토대로 만든 10명의 합성 음성간의 유사도를 비교했습니다. 그 결과 합성된 음성과 실제 음성 사이의 코사인 유사도는 0.6을 넘은 반면, 합성된 음성끼리의 코사인 유사도는 0.7을 넘는 것을 확인할 수 있었습니다.
이는 논문에서 제안한 모델이 목표로 하는 화자의 음성을 어느정도 모방은 가능하나, 합성된 음성과 실제 음성을 충분히 구분할 정도라는 점을 보여줍니다.
3-4. Speaker Embedding Space
실험에 사용한 음성들의 임베딩 벡터를 PCA, t-SNE를 사용하여 시각화했습니다.

위 그림에서 왼쪽은 ground truth의 임베딩과 synthesized의 임베딩을 PCA로 시각화한 것입니다. 실제 음성과 합성된 음성이 서로 겹치면서 가까운 것을 확인할 수 있습니다. 그러나 오른쪽에서 t-SNE로 시각화했을 떄는 실제 음성과 합성된 음성이 완벽히 구분되는 모습을 확인할 수 있습니다. 하지만, 양쪽에서 모두 남성과 여성의 구분이 명확한 점을 볼 때 reasonable한 임베딩이라고 할 수 있습니다.
이러한 결과는 앞선 3-2, 3-3의 정량적인 실험결과들과 일맥상통합니다.
3-5. Number of speaker encoder training speakers

TTS 모델의 일반화 성능은 Speaker encoder가 얼마나 화자에 대한 정보를 잘 표현하는지에 따른다는 생각 하에서 이루어진 실험입니다. 인코더의 훈련 데이터에서의 화자 수에 따라 음성이 어떻게 달라지는 지를 측정했습니다.
화자의 수가 적을 때는 오버피팅을 막기 위해 임베딩 벡터의 차원을 작게 하여 실험을 진행했습니다. 이 실험에서 인코더의 학습에 사용된 화자의 수가 증가함에 따라서 성능이 증가하는 것을 확인할 수 있습니다.
TTS를 위한 데이터보다 speaker encoder에 필요한 데이터의 비용이 훨씬 싸기 때문에 이는 TTS 훈련에 있어서 중요한 결과라고 할 수 있습니다.
3-6. Fictitious speakers

이 실험에서는 음성을 사용해서 임베딩 벡터를 만드는 것이 아니라 임베딩 공간에서 임의의 점을 추출해 가상의 화자를 10명 정한 뒤에 음성을 합성했습니다. 이러한 화자들의 음성을 만들고 자연스러움을 평가했습니다. 훈련에 사용된 화자들과의 코사인 유사도가 0.25보다 낮은 점, 3-3에서 사용한 화자 검증 시스템에서 SV-EER이 높은 점을 보면 이 실험에서 사용된 화자들이 훈련 과정 중에서 등장하지 않은 화자라는 것을 확인할 수 있습니다.
4. 결론 및 총평
논문에서는 Multispeaker speech synthesis를 수행하는 모델에 화자 인코더를 화자 검증이라는 작업에 대해서 훈련시킨 뒤에 전이 학습을 통해 사용하는 것이 유효하다는 것을 보였습니다. 특히, 화자 인코더의 훈련에 등장하는 화자의 수를 증가시킴에 따라 음성 합성의 성능이 좋아진다는 것을 정성적, 정량적으로 보였습니다.
하지만 단일 화자에 대한 TTS 시스템보다는 성능이 떨어진다는 점과 화자에 대한 정보와 발화의 운율을 완전히 구분하지는 못한다는 점이 한계입니다.
사용한 모듈들과 방법에 있어서 독창성이 보이진 않지만 그러한 것들을 잘 조합해서 사용했을 때 좋은 결과를 낼 수 있다는 것을 실험으로 잘 보여줬습니다. 특히 인코더의 화자 수를 늘리는 것으로 성능이 올라간다는 점은 굉장히 유의미한 결과라고 생각합니다.
그러나 설명이 살짝 부족한 부분이 있다고 생각되는데 VCTK와 Librispeech 모델 간의 교차 검증에서 왜 성능저하가 그렇게 심한지에 대해서 부족하다고 생각합니다. 또한 훈련에서는 1.6초 단위로 끊어 인코더를 훈련시키지만 추론시에는 800ms 단위로 50% 오버랩을 해서 수행하는데 이 부분이 왜 그런지에 대해서 설명이 부족하다고 생각합니다.
'Machine Learning' 카테고리의 다른 글
| Flow Matching 설명 (2) | 2024.04.06 |
|---|---|
| so-vits-svc 구조 정리 (2) | 2023.07.01 |
| 연구프로젝트 샘플 (0) | 2021.12.24 |
| 딥러닝을 활용한 음성합성(TTS) 훑어보기(Vocoder) (0) | 2021.09.11 |
| 딥러닝을 이용한 음성합성(TTS) 훑어보기(Text-to-Mel) (0) | 2021.09.08 |


