Buffer Pool은 사실상 page table의 역할을 OS 대신에 하는거나 마찬가지입니다. 그리고 이런 저장장치 간의 속도 차이로 인한 캐싱 이슈는 CS에서 굉장히 고전적인 이슈입니다. OS 수업에서도 page replacement는 들어본 적이 있을 겁니다.
page table에서와 같이 buffer pool도 파일 크기에 비해 작은 메모리를 잘 사용하기 위해서 replacement policy를 잘 세워야 합니다. 사실 누군가가 OS 수업에서 들었을 얘기와 겹치는 부분이 많지만 buffer pool의 replacement policy를 알아봅시다.
Buffer Replacement Policies
먼저 언제 replacement가 일어나는지 알아보자. DBMS가 쿼리를 수행하면서 파일을 읽어들이면 이제 buffer pool이 가득차게 된다. 이러면 이제 현재 있는 frame 중에서 하나를 골라서 해당 frame을 비우고 새로운 페이지를 읽어와야 한다. 이를 replacement라고 한다.
이제 buffer replacement policy는 어떤 frame을 골라서 비울지를 결정하는 방식을 말한다. 이 정책의 목표로는 여러가지가 존재한다.
Correctness
현재 어떤 스레드가 사용중이라고 표시한 그러니까 pinned frame을 비워내면 안된다.
Accuracy
삭제될 frame은 앞으로 제일 적게 사용될 frame이어야 합니다. buffer pool manager의 대목표는 디스크 I/O를 줄이는 것이고 이를 위해서 꼭 필요한 목표입니다.
Speed
어떤 frame을 골라야 할 지를 결정하는 시간은 짧아야 합니다. 굉장히 정확하지만 굉장히 복잡한 알고리즘은 그거 계산하다가 시간 다갑니다. latch 하루죙일 들고 있으면 욕먹는건 당연합니다.
Meta-data overhead
적절한 결정을 위해선 당연히 추가적인 메타데이터가 필요할 것입니다. 그러나 이게 너무 크면 또 말짱 도루묵입니다.
오라클이나 SQL Server 같이 비싼 DBMS를 팔고 있는 곳에선 위의 목적들을 잘 달성하겠지만 여기서 알아볼 것은 비교적 간단하지만 꽤 좋은 방식들입니다.
LRU(Least Recently Used) Replacement
LRU 방식의 컨셉은 간단합니다. 가장 이전에 사용된 페이지는 앞으로도 사용될 확률이 낮을 거라는 가정 하에 그러한 페이지를 비우자는 겁니다. 이를 수행하기 위해서는 각 frame이 언제 사용됐는지에 대한 timestamp를 저장해두고 frame을 비워내야 할 때 선형 탐색을 진행하거나 항상 정렬된 상태로 유지하면서 timestamp가 가장 빠른 페이지를 비워냅니다.
다른 간단한 구현 방식으로는 링크드 리스트를 통해서 페이지들을 관리하는 겁니다. 페이지에 접근이 발생하면 리스트에서 제거한 뒤에 리스트의 끝에 넣습니다. 그리고 삭제해야할 페이지를 찾을 땐 리스트의 제일 앞에서 뽑습니다.
Clock Replacement
Clock 방식은 LRU의 approximation 버전입니다. 각 페이지는 refrence bit라는 메타데이터를 가집니다. 페이지에 접근이 발생하면 해당 페이지의 reference bit가 1이 됩니다.
그리고 페이지들은 circular buffer에 저장되는데 이 때 시곗바늘 같은 것이 스위핑하면서 비워낼 페이지를 찾는 방식입니다.
비워낼 frame을 찾을 땐 포인터가 circular buffer를 스위핑하면서 페이지를 만났을 때 ref bit이 1이라면 0으로 바꾸고 그냥 지나칩니다. 만약 0이라면 그 페이지를 비워냅니다.


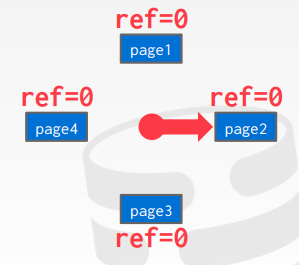
Sequential Flooding
어떤 테이블 전체를 읽어야 되는 쿼리가 발생하게 되면 보통 해당 테이블의 페이지들을 순차적으로 읽게 됩니다.
이 경우 LRU의 가정과는 정확히 반대되는 상황이 일어납니다. 가장 최근에 읽은 것이 제일 다시 쓰일 확률이 낮은거죠.
예시를 살펴봅시다.
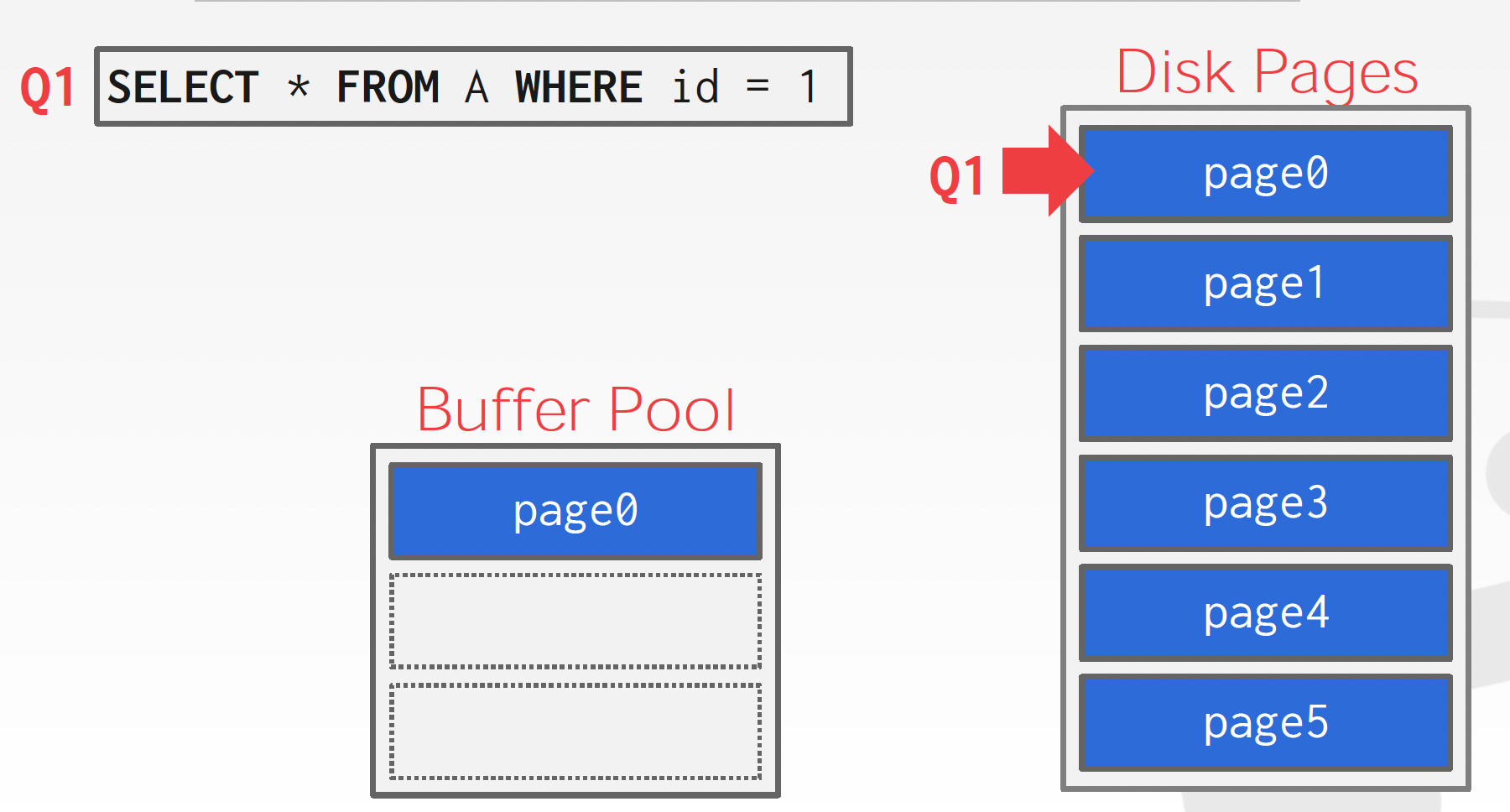


먼저 id가 1인 튜플을 읽어오는 쿼리 Q1을 실행해서 0번 페이지만 buffer pool에 올라옵니다.
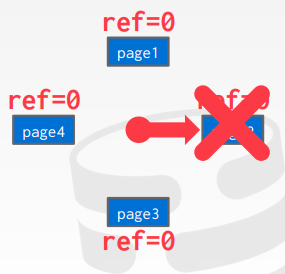
그리고 테이블 전체를 읽는 쿼리 Q2가 진행됩니다. Q2가 페이지 3을 읽을 때 0번 페이지가 buffer pool에서 지워집니다. 이러고 다시 id가 1인 튜플을 읽는 쿼리가 실행되면 0번 페이지를 다시 읽어와야 합니다.
만약 Q2가 페이지 3을 읽어올 때 최근에 읽었던 페이지 2를 비워냈다면 이런 miss가 발생하지 않았습니다.
이런 상황에도 대응할만한 정책을 몇 가지 알아봅시다.
LRU-K
LRU-K 방식은 각 페이지 별로 최근 K개의 접근기록을 관리하면서 각 접근 사이의 시간을 기준으로 각 접근 사이의 시간이 길수록 이후에 금방 필요해지진 않을 거라는 가정하에 희생될 페이지를 찾습니다.
Localization
각 쿼리나 트랜잭션별로 정책과 버퍼 풀을 두는 것입니다. 예를 들어서 LRU 방식을 취하되 현재 실행되고 있는 쿼리에게 있어서 최근에 제일 덜 사용된 페이지를 고르는 것입니다. 혹은 특정 트랜잭션은 정책을 아예 바꿔서 가장 최근에 사용된 페이지를 없애도록 하거나도 가능할 수 있습니다.
postgreSQL의 경우 쿼리별로 사용가능한 buffer pool의 크기가 초기에 정해져있고 쿼리가 더 많이 실행될수록 그 크기를 늘려서 할당하는 방식을 통해서 localization을 합니다.
Priority Hint
쿼리나 트랜잭션이 실행 중일 때 특정 페이지는 다른 페이지보다 중요하니까 가능하면 buffer pool에 계속 두라고 힌트를 주는 것도 가능합니다.
예를 들어서 트리 인덱스의 루트 페이지는 정말 많이 인덱스를 사용할 때는 무조건 접근이 일어나는 페이지이기 때문에 가능한 비우지 말라고 하는 것입니다.
Dirty Page
페이지가 갖고 있어야할 중요한 메타데이터로 dirty bit이 있습니다. 이는 buffer pool로 올라온 뒤에 페이지의 내용에 변경이 생겨서 비워낼 때 디스크에 이를 기록해야 하느냐를 담고 있습니다.
희생될 페이지를 찾을 때 dirty page를 고른다면 디스크 I/O가 발생해서 느려집니다. 이를 막기 위해서 dirty page를 제외하고 희생될 페이지를 찾게 되면 굉장히 빨라지지만 dirty page들 중에 접근이 잘 발생하지 않는 페이지가 있다면 이는 메모리의 낭비일 뿐입니다.
이런 문제를 해결하기 위한 방식으로 주기적으로 dirty page들을 디스크에 쓰는 방법이 있습니다. 다만 이를 수행할 때 로그와의 동기화나 integrity 등 신경써야할 부분이 꽤 있어서 마냥 쉬운 작업은 아닙니다.
'DB 공부' 카테고리의 다른 글
| 해시 테이블(Hash Table) (0) | 2021.08.26 |
|---|---|
| Buffer Pool Manager - 1 (1) | 2021.06.23 |
| DBMS는 저장소를 어떻게 관리하는가? - 2 (2) | 2021.06.08 |
| DBMS는 저장소를 어떻게 관리하는가? (0) | 2021.06.02 |
| SQL에서 NULL과의 연산 (0) | 2021.05.21 |



